Multiple read models can be derived from a single data point
If you follow architectural patterns like CQRS to separate the write side of your application from the read side, you have the advantage of designing your Read Models to fit hand-in-glove with query requirements.
You should go further and construct as many Read Models you want to cater to the different requirements of consuming applications.
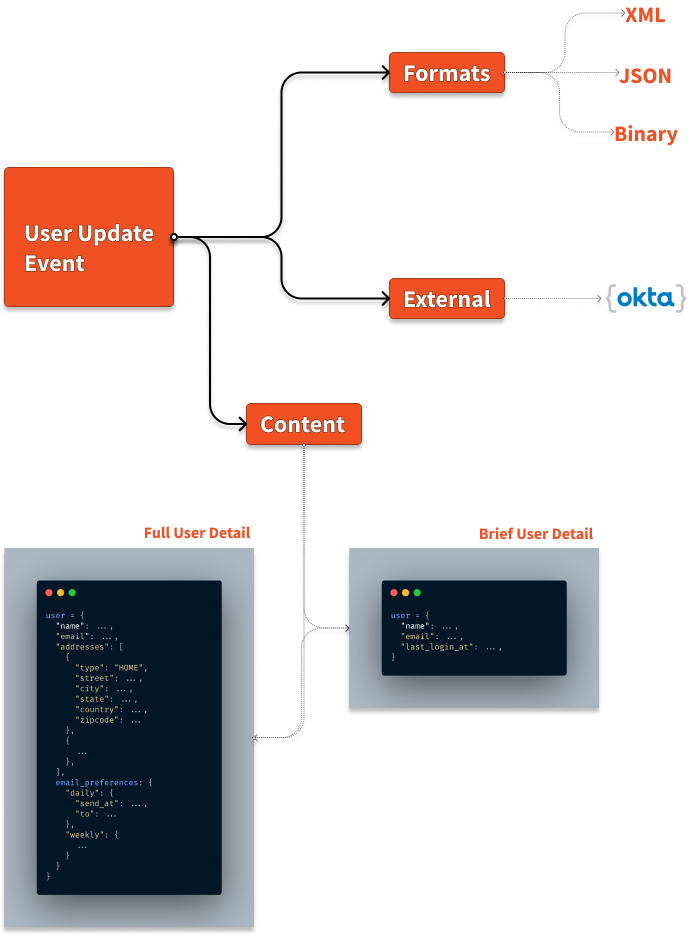
Most applications use the same piece of data in different contexts. For example, it is not uncommon for an application frontend to request the entire user record after a successful login. But it may also need a smaller subset of data of many users to display as part of the user administration page.
You have the chance to optimize data transferred by constructing a full Read Model containing the entire user profile and a brief Read Model that fits the latter requirement.
If your application is part of an ecosystem, different systems may request the same data in other formats. Since Read Models can store ready-to-ship information, you can store data in various ready-to-serve formats, like XML, JSON, or even binary encodings.
Sometimes, Data Locality can play an important role in a globally distributed application. Suppose a consuming application is on a different cloud, or your app data needs to be co-located within a larger data pool. In that case, you can maintain a custom Read Model meant only to serve one specific consuming application.
Also, Data in Read Models is expendable and Read Models are usually stored in schemaless databases. So it is pretty easy to add new read models or completely wipe out and rebuild existing models from scratch, minimizing the effort required to maintain multiple read models.
Take care that Read Models hold autonomous data, though. Joins between Read Models introduces the need for transactions limiting your options on databases.